Model Quantization
As the FuriosaAI Warboy NPU only supports 8-bit integer models, the Furiosa SDK provides a tool that quantizes* FP16 and FP32 real data type based models and converts them into 8-bit integer data type models. The quantization tool provided by the FuriosaAI SDK allows for the acceleration a wider variety of models using the NPU.
*Quantization is a common technique used to increase the processing performance of a model or accelerate hardware.
The quantization method supported by FuriosaAI SDK is based on post-training 8-bit quantization and follows Tensorflow Lite 8-bit quantization specification.
ONNX models can be converted to an 8-bit quantization model using the API and command line tools provided by the SDK. Usage instructions can be found at the link below:
TensorFlow models will be supported later.
How it works
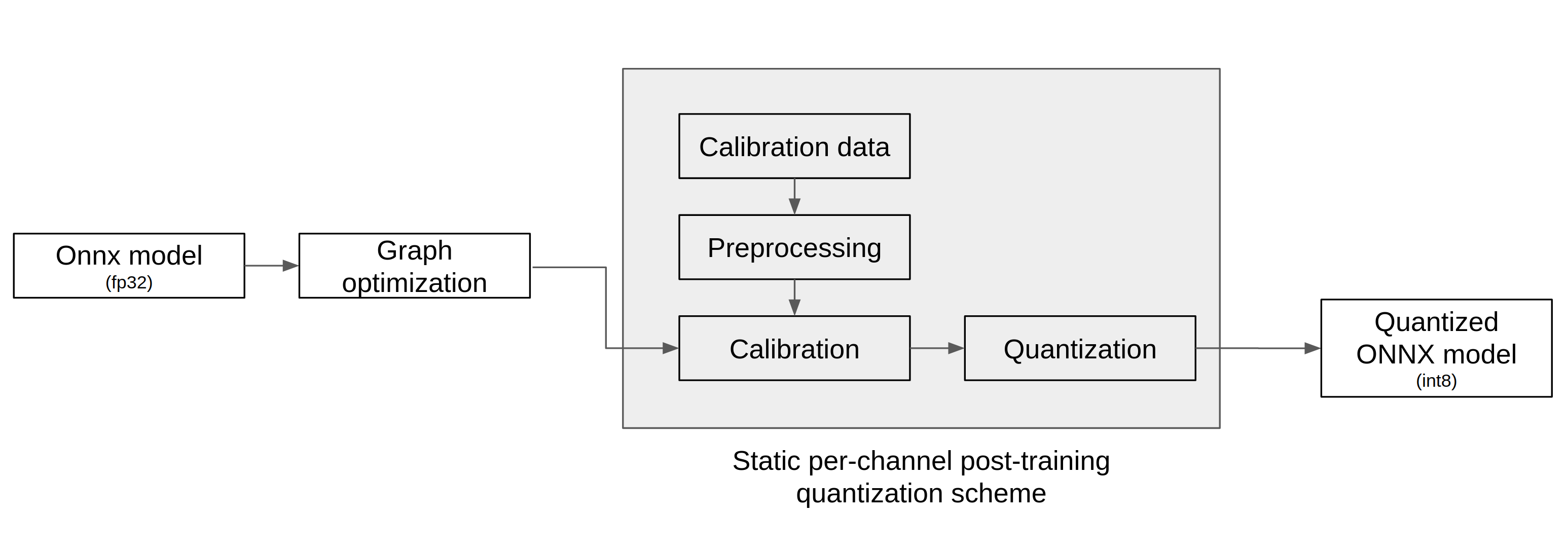
As shown in the figure below, the quantization tool receives a ONNX model as an input, performs quantization through the following three steps, and outputs a quantized ONNX model.
Graph optimization
Calibration
Quantization