Model Quantization
Furiosa SDK and first generation Warboy support INT8 models. To support floating point models, Furiosa SDK provides quantization tools to convert FP16 or FP32 floating point data type models into INT8 data type models. Quantization is a common technique used to increase model processing performance or accelerate hardware. Using the quantization tool provied by Furiosa SDK, a greater variety of models can be accelerated by deploying the NPU.
Quantization method supported by Furiosa SDK is based on post-training 8-bit quantization, and follows Tensorflow Lite 8-bit quantization specification.
How It Works
As shown in the diagram below, the quantization tool receives the ONNX model as input, performs quantization through the following three steps, and outputs the quantized ONNX model.
Graph Optimization
Calibration
Quantization
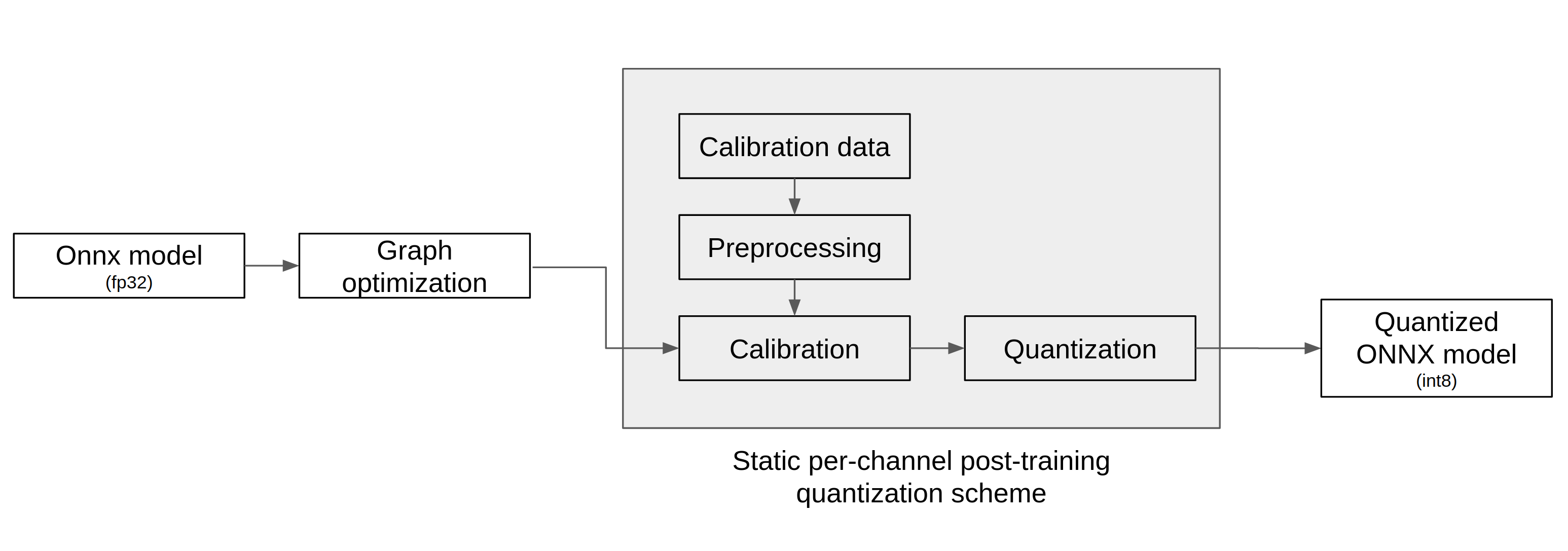
In the graph optimization process, the topological structure of the graph is changed by adding or replacing operators in the model through analysis of the original model network structure, so that the model can process quantized data with a minimal drop in accuracy.
In the calibration process, the data used to train the model is required in order to calibrate the weights of the model.
Accuracy of Quantized Models
The table below compares the accuracy of the original floating-point models with that of the quantized models obtained using the quantizer and various calibration methods provided by Furiosa SDK:
Model |
FP Accuracy |
INT8 Accuracy (Calibration Method) |
INT8 Accuracy ÷ FP Accuracy |
|---|---|---|---|
ConvNext-B |
85.8% |
80.376% (Asymmetric MSE) |
93.678% |
EfficientNet-B0 |
77.698% |
73.556% (Asymmetric 99.99%-Percentile) |
94.669% |
EfficientNetV2-S |
84.228% |
83.566% (Asymmetric 99.99%-Percentile) |
99.214% |
ResNet50 v1.5 |
76.456% |
76.228% (Asymmetric MSE) |
99.702% |
RetinaNet |
mAP 0.3757 |
mAP 0.37373 (Symmetric Entropy) |
99.476% |
YOLOX-l |
mAP 0.497 |
mAP 0.48524 (Asymmetric 99.99%-Percentile) |
97.634% |
YOLOv5-l |
mAP 0.490 |
mAP 0.47443 (Asymmetric MSE) |
96.822% |
YOLOv5-m |
mAP 0.454 |
mAP 0.43963 (Asymmetric SQNR) |
96.835% |
Model Quantization APIs
You can use the APU and command line tool provided in this SDK to convert an ONNX model into an 8bit quantized model.
Refer to the links below for further instructions.