FuriosaAI Warboy
FuriosaAI’s first generation NPU Warboy is a chip with an architecture optimized for deep learning inference. It demonstrates high performance for deep learning inference while maintaining cost-efficiency. FuriosaAI Warboy is optimized for inferences with low batch sizes; for inference requests with low batch sizes, all of the chip’s resources are maximally utilized to achieve low latency. The large on-chip memory is also able to retain most major CNN models, thereby eliminating memory bottlenecks, and achieving high energy efficiency.
Warboy supports key CNN models used in various vision tasks, including Image Classification, Object Detection, OCR, Super Resolution, and Pose Estimation. In particular, the chip demonstrates superior performance in computations such as depthwise/group convolution, that drive high accuracy and computational efficiency in state-of-the-art CNN models.
Warboy delivers 64 TOPS performance and includes 32MB of SRAM. Warboy consists of two processing elements (PE), which each delivers 32 TOPS performance and can be deployed independently. With a total performance of 64 TOPS, should there be a need to maximize response speed to models, the two PEs may undergo fusion, to aggregate as a larger, single PE. Depending on the users’ model size or performance requirements the PEs may be 1) fused so as to minimize response time, or 2) utilized independently to maximize throughput.
FuriosaAI SDK provides the compiler, runtime software, and profiling tools for the FuriosaAI Warboy. It also supports the INT8 quantization scheme, used as a standard in TensorFLow and PyTorch, while providing tools to convert Floating Point models using Post Training Quantization. With the FuriosaAI SDK, users can compile trained or exported models in formats commonly used for inference (TFLite or ONNX), and accelerate them on FuriosaAI Warboy.
HW Specifications
The chip is built with 5 billion transistors, dimensions of 180mm^2, clock speed of 2GHz, and delivers peak performance of 64 TOPS of INT8. It also supports a maximum of 4266 for LPDDR4x. Warboy has a DRAM bandwidth of 66GB/s, and supports PCIe Gen4 8x.
Peak Performance |
64 TOPS |
On-chip SRAM |
32 MB |
Host Interface |
PCIe Gen4 8-lane |
Form Factor |
Full-Height Half-Length (FHHL)
Half-Height Half-Length (HHHL)
|
Thermal Solution |
Passive Fan
Active Fan
|
TDP |
40 - 60W (Configurable) |
Operating Temperature |
0 ~ 50℃ |
Clock Speed |
2.0 GHz |
DDR Speed |
4266 Mbps |
Memory Type |
LPDDR4X |
Memory Size |
16 GB (max. 32 GB) |
Peak Memory Bandwidth |
66 GB/s |
List of Supported Operators for Warboy Acceleration
FuriosaAI Warboy and SDK can accelerate the following operators, as supported by Tensorflow Lite model and ONNX.
The names of the operators use ONNX as a reference.
Note
Any operators cannot be accelerated on Warboy, the operators will run on the CPU. For some operators, even if Warboy acceleration is supported, if certain conditions are not met, they may be split into several operators or may run on the CPU. Some examples of this would be when the weight of the model is larger than Warboy memory, or if the Warboy memory is not sufficient to process a certain computation.
Name of operator |
Additional details |
|---|---|
Acceleration supported, only if after Conv |
|
Acceleration supported, only for height axis |
|
Acceleration supported, only for group <= 128 and dilation <= 12 |
|
Acceleration supported, only for p = 2 and batch <= 2 |
|
Acceleration supported, only for mode=”CRD” and Furiosa SDK version 0.6.0 or higher |
|
Acceleration supported, only for height axis |
|
Acceleration supported, only for batch <= 2 |
|
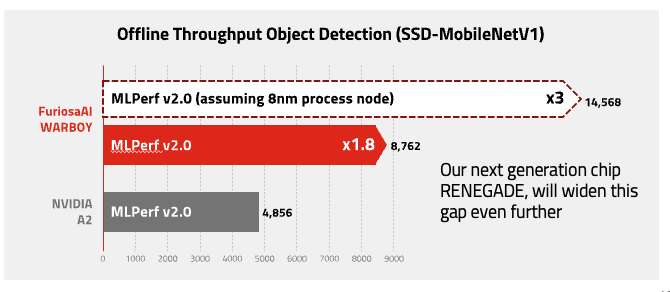
MLPerf
Results submitted to MLPerf can be found at MLPerf™ Inference Edge v2.0 Results