Release Notes - 0.7.0
Furiosa SDK 0.7.0은 메이저 릴리즈로 다수의 성능 개선, 기능 추가, 버그픽스에 대한 약 1400여개의 커밋을 포함하고 있다.
패키지 이름 |
버전 |
|---|---|
NPU Driver |
1.3.0 |
HAL (Hardware Abstraction Layer) |
0.8.0 |
Furiosa Compiler |
0.7.0 |
Python SDK (furiosa-runtime, furiosa-server, furiosa-serving, furiosa-quantizer, ..) |
0.7.0 |
NPU Device Plugin |
0.10.0 |
NPU Feature Discovery |
0.1.0 |
NPU Management CLI (furiosactl) |
0.9.1 |
업그레이드 방법
APT 저장소를 사용하고 있다면 다음과 간단히 업그레이드할 수 있다. APT 저장소 설정 및 설치 방법에 대한 자세한 설명은 드라이버, 펌웨어, 런타임 설치 가이드 에서 찾을 수 있다.
apt-get update && \ apt-get install -y furiosa-driver-pdma furiosa-libnux pip install --upgrade furiosa-sdk
주요 변경 사항
더 많은 연산자가 가속되도록 컴파일러 개선
컴파일러 개선을 통해 더 많은 연산자가 다양한 조건에서 가속될 수 있게 되었다. 0.7.0에서 추가된 가속 연산자와 조건은 아래에서 확인할 수 있으며 가속 연산자의 전체 리스트는 가속 지원 연산자 목록 에서 찾을 수 있다.
Resize 연산자의 Linear 및 Nearest 모드 지원 추가
SpaceToDepth 연산자의 DCR 모드 지원 추가
DepthToSpace 연산자의 DCR 모드 지원 추가
Pad 연산자의 CHW axis 지원 추가
Slice 연산자의 C axis 지원 추가
Tanh, Exp, Log 연산자에 대한 가속 지원
Concat의 C axis 지원
Dilation이 최대 12까지 지원되도록 개선
Gelu, Erf, Elu 연산자 가속 지원
컴파일러 캐시 도입
컴파일러 캐시는 모델의 바이너리와 속성에 기반한 해쉬 값과 컴파일 결과를 함께 저장하여 동일한 모델을 컴파일 할 때 결과를 재활용하게 한다. 로컬 파일 시스템 ($HOME/.cache/furiosa/compiler) 또는 Redis를 캐쉬 스토리지로 활용할 수 있으며 자세한 사용법은 컴파일러 캐쉬 (Compiler Cache) 에서 찾아볼 수 있다.
컴파일러 힌트 도입
session.create() 과 같이 컴파일 과정을 수반하는 함수 실행 시
아래와 같이 컴파일러 로그가 저장된 경로가 출력된다.
Saving the compilation log into /home/furiosa/.local/state/furiosa/logs/compile-20211121223028-l5w4g6.log
로그에는 기본적으로 컴파일 과정을 이해하는 유용한 정보를 담고 있는데 0.7.0 버전 부터 성능 개선에 유용한 힌트를 추가로 출력한다.
cat <log file> | grep Hint 커맨드로 힌트만 출력해볼 수 있다. 힌트는 어떤 연산자를 왜 가속되지 않는지를 알려준다.
cat /home/furiosa/.local/state/furiosa/logs/compile-20211121223028-l5w4g6.log | grep Hint 2022-05-24T02:44:11.399402Z WARN nux::session: Hint [19]: 'LogSoftmax' cannot be accelerated yet 2022-05-24T02:44:11.399407Z WARN nux::session: Hint [12]: groups should be bigger than 1 2022-05-24T02:44:11.399408Z WARN nux::session: Hint [17]: Softmax with large batch (36 > 2) cannot be accelerated by Warboy
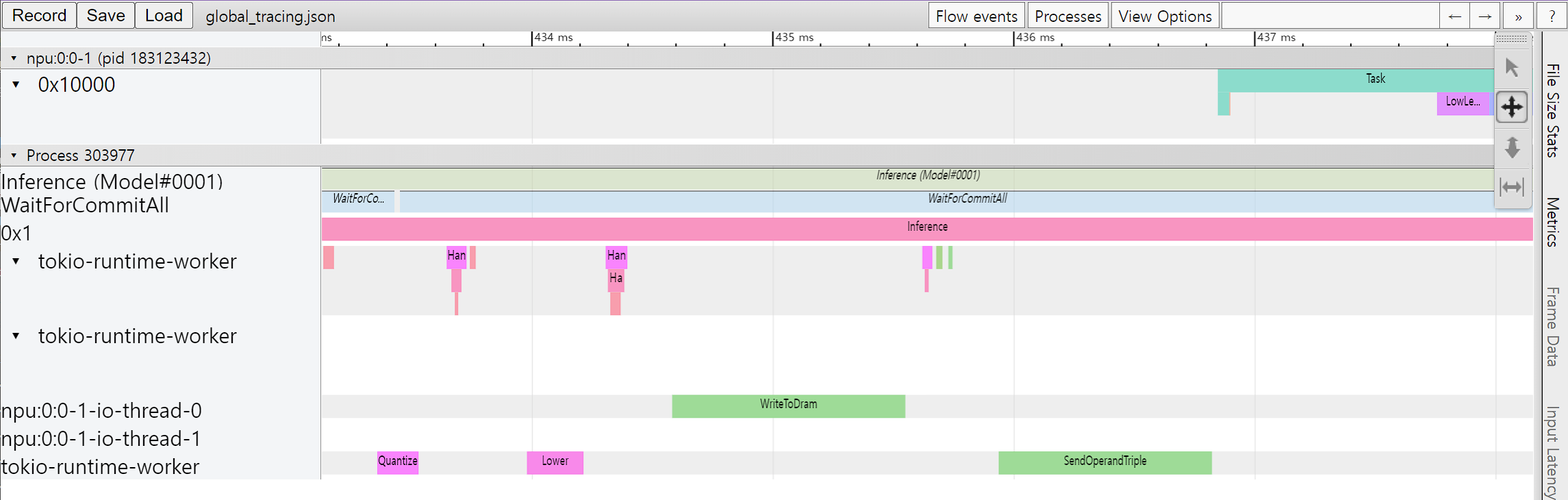
성능 프로파일링 도구 도입
모델 추론(inference) 과정에서 수행되는 시간을 단계별로 측정하여 볼 수 있는 프로파일링 기능이 도입되었다. 환경변수 또는 Python 코드 내에서 프로파일링 컨텍스트를 통해 프로파일러를 활성화 할 수 있다. 자세한 사용법은 성능 프로파일링 에서 찾아볼 수 있다.
Python SDK 개선
session.create()및session.create_async()함수가 배치 사이즈를 인자로 받도록 개선session.create()및session.create_async()에서 파라메터로 전달된 컴파일러 옵션이 반영되지 않는 버그 수정
아래는 배치 사이즈와 컴파일러 옵션을 사용 하는 예이다.
config = { "without_quantize": { "parameters": [{"permute": [0, 2, 3, 1]}] } } with session.create("model.onnx", batch_size=2, compile_config=config) as sess: outputs = sess.run(inputs)
양자화 도구
ONNX Squeeze 연산자 OpSet 12 이하 버전에서 axes 속성이 지정되어 있지 않은 경우에도 출력 텐서의 모양을 추론할 수 있도록 수정
NxCxHxW 모양을 가진 텐서를 입력으로 받는 Conv 뿐만 아니라, NxCxD 모양을 가진 입력 텐서를 받는 Conv에 대한 지원 추가
Conv가 편향(bias)을 입력으로 받지 않는 경우에도 “Conv - BatchNormalization” 부분 그래프를 Conv로 융합할 수 있도록 수정
양자화 이후 과정에서 일관된 방식으로 모델을 처리할 수 있도록, 피연산자가 초기값을 가지는지 여부와 상관없이 Sub, Concat과 Pow 연산자를 항상 QDQ 형식으로 양자화하도록 수정
양자화 과정 및 결과 모델에서 ONNX Runtime 관련 경고가 나지 않도록 수정
텐서 모양 정보를 추론하지 못 하는 경우를 빠짐없이 발견하도록 검사 조건을 강화
float32 형 데이터를 입력으로 받는 모델 뿐만 아니라 다른 소수점 형이나 정수 형을 입력으로 받는 모델도 랜덤 캘리브레이션할 수 있도록 수정
이미 양자화된 모델이 주어졌을 때를 보다 안정적으로 발견하고 종료하도록 수정
Conv의 데이터 입력 혹은 가중치(weight)의 스케일(scale)이 너무 작아 편향(bias)의 스케일이 0이 되는 경우 가중치의 스케일을 적절히 조절하도록 수정
“Gather - MatMul” 부분 그래프를 Gather로 융합할 수 있는 경우에 대한 조건 강화
사용하는 의존 라이브러리들을 최신 버전으로 갱신
Device Plugin의 파일 기반 설정 도입
Kubernetes에서 사용하는 NPU Device Plugin의 실행 옵션을 파일로 설정하는 기능이 추가되었다. 기존처럼 명령행 인자로 옵션 항목들을 입력하거나, 설정 파일을 선택하여 옵션을 지정할 수 있다. 자세한 사용법은 Kubernetes 지원 에서 찾아볼 수 있다.
Furiosa Model에 blocking API 도입
모델 바이너리를 가져오는 작업은 네트워크를 통해 무거운 파일을 가져오는 것이라 0.5.0 에서
non-blocking API로 작성되었지만, 0.7.0 부터 개발 편의성을 위해 blocking API를 기본으로 노출한다.
기존의 non-blocking API는 furiosa.models.nonblocking 의 하위 모듈을 통해 접근할 수 있다.
- 기존 코드
import asyncio from furiosa.registry import Model from furiosa.models.vision import MLCommonsResNet50 resnet50: Model = asyncio.run(MLCommonsResNet50())
- 동일한 기능을 하는 0.7.0 코드 (blocking API 사용)
from furiosa.registry import Model from furiosa.models.vision import MLCommonsResNet50 resnet50: Model = MLCommonsResNet50()
- 동일한 기능을 하는 0.7.0 코드 (non-blocking API 사용)
import asyncio from furiosa.registry import Model from furiosa.models.nonblocking.vision import MLCommonsResNet50 resnet50: Model = asyncio.run(MLCommonsResNet50())