모델 양자화
모델 양자화는 모델 경량화를 위한 보편적인 방법 중 하나로, 추론에 사용되는 weight와 activation 등을 낮은 정밀도로 표현하는 기술이다. 양자화를 거치면 모델을 더 적은 비트로 표현할 수 있어 메모리 요구량이 줄어들고, 하드웨어에서 더 효율적으로 처리가 가능해져 추론 속도를 향상시킬 수 있다.
FuriosaAI의 1세대 NPU인 Warboy는 8bit 정수형(int8) 모델만 지원한다. FuriosaAI SDK는 실수형 데이터 타입 기반의 모델을 지원하기 위해 실수형 데이터 타입인 float32 기반 모델을 양자화하여 int8 데이터 타입 모델로 변환하는 도구를 제공한다. 이 도구를 사용하면 NPU를 활용하여 다양한 모델을 가속할 수 있다.
FuriosaAI SDK가 지원하는 양자화 방식은 post-training 8-bit quantization 기반이며 Tensorflow Lite 8-bit quantization specification 을 따른다.
데이터 타입
일반적으로 AI 모델은 float32 타입을 기반으로 정의되고 있다. float32 타입은 표현할 수 있는 범위가 넓고 수를 정밀하게 표현할 수 있다. 반면 int8 타입은 표현할 수 있는 범위가 좁고 표현 가짓수가 256개에 불과하다. 그러나 추론 단계에서는 int8이 float32보다 유리한 이유가 몇 가지 있다.
정수형 타입의 연산이 실수형 타입의 연산보다 빠르므로 같은 시간동안 더 많은 계산을 할 수 있다.
정수형 타입의 연산이 실수형 타입의 연산보다 컴퓨팅 파워를 적게 사용한다.
정수형 타입의 값이 실수형 타입의 값보다 메모리를 적게 사용한다.
참고
그 밖의 데이터 타입 예시 (Warboy 미지원)
float16: 실수형 타입이며 부호 1비트, 지수 5비트, 가수 10비트를 사용
bfloat16: 실수형 타입이며 부호 1비트, 지수 8비트, 가수 7비트를 사용
int4: 정수형 타입이며 수를 표현하는데 4비트를 사용
양자화에 대한 산술 표현
실수형 타입에서 정수형 타입으로의 변환은 다음 수식을 통해 표현할 수 있다. 실숫값을 scale(s) 로 나누고 zero-point(z) 를 더한 후 반올림한다.
정수형 타입에서 실수형 타입으로의 변환은 다음 수식을 통해 표현할 수 있다. 정숫값에 zero-point를 빼고 scale을 곱하면 실숫값을 계산할 수 있다.
정수 q가 int8 타입이면 표현할 수 있는 실수 범위는 다음과 같다.
한계점
실수형 타입의 값을 정수형에 대응시키면 필연적으로 오차가 발생한다.
예를 들어, scale은 10.0이고 zero-point는 0이라고 가정하자.
실수 20.0에 대한 양자화된 정수는 2이고 실수 30.0에 대한 양자화된 정수는 3이다.
이때 20.0과 30.0 사이에 있는 값들을 양자화 시 20.0이나 30.0에 해당하는 2 또는 3이 될 수밖에 없으므로 오차가 발생한다.
이를 양자화 오류라고 부른다.
int8 양자화의 경우 일반적으로 다음 범위의 오차가 발생한다.
양자화 체계
대칭 양자화(Symmetric Quantization)
표현할 수 있는 실수의 범위가 0을 기준으로 대칭인 형태이다.
zero-point를 0으로 고정하면 연산량이 줄어든다.
0을 기준으로 대칭을 유지하기 때문에 원본 범위 양극단의 절댓값이 크게 차이 난다면, 반대 부호 쪽에서도 불필요하게 넓은 범위를 포함해야 한다.
범위가 불필요하게 넓어짐에 따라 실수에 대한 표현력이 낮아지고 scale 값이 커져 양자화 오차도 커지게 된다.
예를 들어 Relu 연산의 결과 범위는 [0, a]이다. 이때 대칭 양자화를 적용하면 범위가 [-a, a]가 되기 때문에 불필요한 음수 영역의 확장으로 인해 양자화 오차가 커지게 된다.
int8에도 대칭 양자화를 적용할 수 있다.
int8의 범위가 [-128, 127]이기 때문에, zero-point가 0이 될 수 없다.
표현 범위의 손해를 감수하고, zero-point를 0으로 사용하기 위해 int8의 범위를 [-127, 127]로 사용할 수 있다.
비대칭 양자화(Asymmetric Quantization)
대칭 양자화와 달리 실수 범위의 중심이 0일 필요가 없어 더 정교한 양자화가 가능하다.
비대칭 양자화는 대칭 양자화와 달리 zero-point를 계산에 포함하여 하드웨어 구현이 상대적으로 복잡하다.
Warboy는 비대칭 양자화 방식을 지원한다. 그리고 다양한 보정 방식을 제공하고 있다.
양자화 매개변수
텐서에 양자화 매개변수를 지정하는 방식은 두 가지로 나뉜다. Warboy는 activation에는 텐서별 양자화 방식을, convolution의 weight와 bias는 채널별 양자화 방식을 적용하고 있다.
텐서별 양자화
텐서의 양자화 매개변수를 하나로 고정한다.
텐서 내의 모든 원소들이 같은 양자화 매개변수를 가지게 된다.
채널별 양자화
텐서의 한 축에 대해 여러 개의 양자화 매개변수를 가진다.
텐서별 양자화 방식과 달리 각 원소 묶음마다 다양한 양자화 매개변수를 가질 수 있어 보다 정확하게 실수를 표현할 수 있다.
보정 (calibration)
양자화 과정 중 표현하고자 하는 실수의 범위를 결정하는 것은 중요한 단계이다. 이 실수의 범위를 계산하고 구하는 과정을 보정(calibration)이라고 한다. 이 과정을 통해 산출된 실수 범위를 보정 범위(calibration range)라고 한다. 보정 방식은 크게 두 가지로 분류된다.
PTQ (Post Training Quantization)
학습을 마친 원본 모델을 기반으로 activation, weight의 보정 범위를 구한다. 모델에 입력값을 넣어 실행하고 각 activation 에서 사용되는 원솟값들을 기반으로 보정 범위를 구한다. PTQ는 두 가지 방식으로 나누어진다.
Post Training Dynamic Quantization
모델을 실행하는 시점에 입력으로 들어온 값을 기반으로 보정 범위를 구한다.
실행 시점 이전에는 보정 범위를 계산할 필요가 없다.
실행 시점에 보정 범위를 계산하기 때문에 오버헤드가 발생한다.
Post Training Static Quantization
보정 범위를 실행 시점 이전에 미리 계산하고 모델에 기록해 둔다.
모델에 이미 기록된 값을 사용하므로 실행 시점에는 오버헤드가 없다.
보정 범위를 계산하기 위해 보정용 데이터 셋이 필요하다.
QAT (Quantization Aware Training)
모델을 학습하는 시점에 양자화를 고려해서 보정 범위를 계산한다.
FuriosaAI SDK의 보정 방식 (Calibration Method)
FuriosaAI SDK는 기본적으로 Post Training Static Quantization을 보정 방식으로 사용하고 있다. 현재 5개의 계산 방법을 제공하고 각 방법별로 대칭/비대칭 양자화를 지원한다.
Method |
Asymmetric |
Symmetric |
|---|---|---|
MIN_MAX |
MIN_MAX_ASYM |
MIN_MAX_SYM |
ENTROPY |
ENTROPY_ASYM |
ENTROPY_SYM |
PERCENTILE |
PERCENTILE_ASYM |
PERCENTILE_SYM |
SQNR |
SQNR_ASYM |
SQNR_SYM |
MSE |
MSE_ASYM |
MSE_SYM |
범위
보정 범위를 어떤 형태로 저장할지에 따라 두 가지로 나뉜다.
대칭형 (
SYM)Symmetric Quantization 방식으로 범위가 대칭형으로 정해진다.
단, 범위 내의 값이 모두 양수일 경우 [-a, a]가 아닌 [0, a]로 산출된다.
이를 통해 모든 원소의 값들이 양수임에도 불구하고 음수 영역으로 범위가 확장되어 실수 표현력이 저해되는 문제를 해결할 수 있다.
비대칭형 (
ASYM)Asymmetric Quantization 방식으로 범위가 비대칭형으로 정해진다.
산출 방법
보정 범위를 계산하는 방법을 5가지 제공하고 있다. 값 자체만 고려하여 계산하는 방식과, 값의 분포 즉 히스토그램을 바탕으로 계산하는 방식으로 나뉜다.
비 히스토그램 기반
MIN_MAX텐서의 원소 중 최솟값과 최댓값을 보정 범위로 지정한다.
분포에서 크게 벗어나 존재하는 원솟값(outlier)이 있을 경우 범위가 과도하게 넓게 잡히는 단점이 있다.
히스토그램 기반
ENTROPY양자화 전의 분포와 양자화 후의 분포가 가장 유사한 보정 범위를 찾는다.
원솟값들이 많이 분포되어 있는 곳을 최대한 많이 표현하는 범위를 찾는다.
PERCENTILE어느 퍼센티지만큼 표현할지 입력으로 받아, 원솟값 분포에서 해당 퍼센티지를 포함할 수 있는 범위를 찾는다.
outlier에 취약한 MIN_MAX의 단점을 보완할 수 있다.
SQNR: Signal-to-quantization-noise Ratio원솟값을 양자화 후 다시 실수로 만들었을 때 오차가 작은 보정 범위를 찾는다.
참고: https://en.wikipedia.org/wiki/Signal-to-quantization-noise_ratio
MSE: Mean squared errorSQNR과 같은 방식이나, 오차를 계산할 때 평균 제곱 오차(mean squared error)를 이용한다.
FuriosaAI SDK의 양자화 과정
양자화 도구는 아래 그림에서 표현된 바와 같이 ONNX 모델을 입력으로 받아 아래 3단계를 거쳐 양자화를 실행하고 양자화된 ONNX 모델을 출력한다.
그래프 최적화(Graph Optimization)
보정(Calibration)
양자화(Quantization)
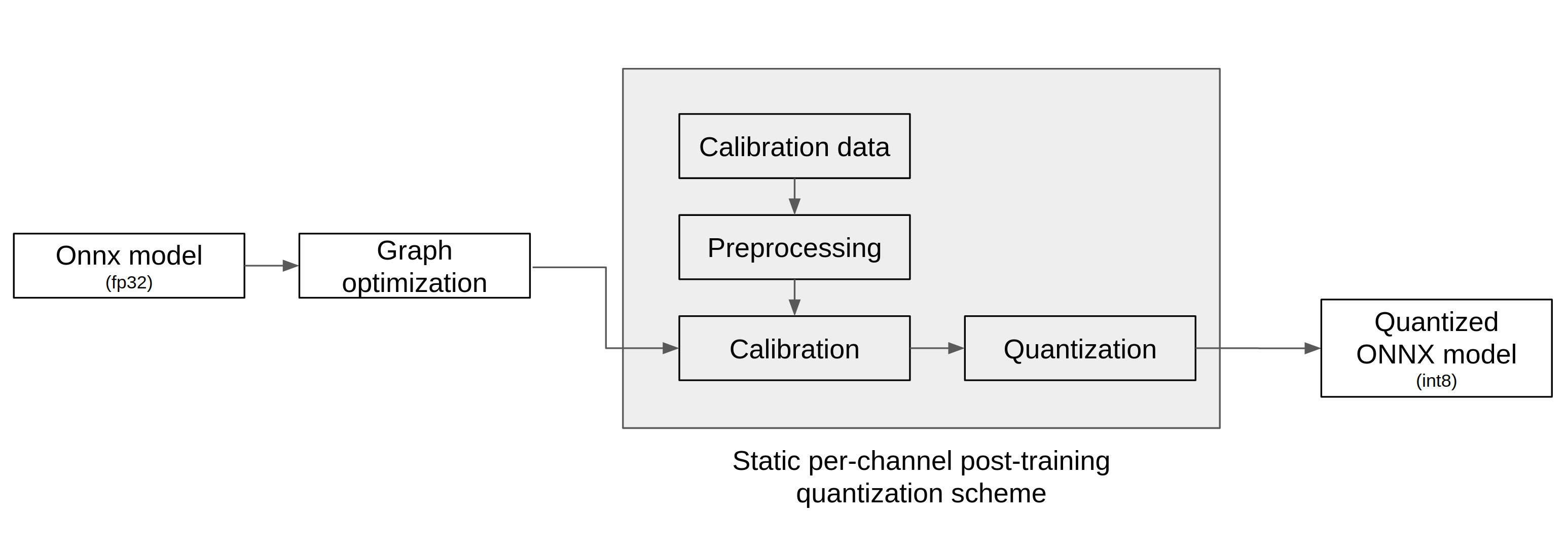
그래프 최적화 과정에서는 모델이 양자화된 데이터를 정확도 저하를 최소화하면서 처리할 수 있도록 원본 모델 네트워크의 구조를 분석하여 모델에 연산자를 추가하거나 대체하여 그래프의 위상구조를 변경한다.
보정 과정에서는 데이터를 기반으로 모델의 weight를 보정하며 이 과정에서 모델을 학습할 때 사용했던 데이터가 필요하다.
양자화 모델의 정확도
아래 표는 FuriosaAI SDK에서 제공하는 Quantizer와 다양한 보정 방법을 이용해 여러 모델을 양자화하고 원본 소수점 모델과 정확도를 비교한 것이다.
Model |
FP Accuracy |
int8 Accuracy (Calibration Method) |
int8 Accuracy ÷ FP Accuracy |
|---|---|---|---|
ConvNext-B |
85.8% |
80.376% (Asymmetric MSE) |
93.678% |
EfficientNet-B0 |
77.698% |
73.556% (Asymmetric 99.99%-Percentile) |
94.669% |
EfficientNetV2-S |
84.228% |
83.566% (Asymmetric 99.99%-Percentile) |
99.214% |
ResNet50 v1.5 |
76.456% |
76.228% (Asymmetric MSE) |
99.702% |
RetinaNet |
mAP 0.3757 |
mAP 0.37373 (Symmetric Entropy) |
99.476% |
YOLOX-l |
mAP 0.497 |
mAP 0.48524 (Asymmetric 99.99%-Percentile) |
97.634% |
YOLOv5-l |
mAP 0.490 |
mAP 0.47443 (Asymmetric MSE) |
96.822% |
YOLOv5-m |
mAP 0.454 |
mAP 0.43963 (Asymmetric SQNR) |
96.835% |
ModelEditor API
모델을 양자화하면 각 연산의 입출력 텐서는 정수 자료형으로 변경되지만, 모델 자체의 입출력 텐서는 원본의 실수 자료형이 유지된다. 그래서 모델 추론 시작 부분에 실숫값을 정숫값으로 형 변환하는 연산과 모델 추론 종료 부분에 정숫값을 실숫값으로 형 변환하는 연산이 덧붙는다.
필요하다면 모델 자체의 입력 또는 출력 텐서도 정수 자료형으로 변경하고, 위 연산들을 제거하여 모델을 최적화할 수 있다.
다음 API를 사용해 형 변환을 적용할 수 있다.
editor = ModelEditor(onnx_model)
# input 텐서의 자료형을 uint8로 변환
editor.convert_input_type('input', TensorType.UINT8)
# output 텐서의 자료형을 int8로 변환
editor.convert_output_type('output', TensorType.INT8, (0, 1))
위 API에 대한 자세한 설명은 성능 최적화 문서 를 참고할 수 있다.
모델 양자화 APIs
모델 양자화의 이해를 돕기 위한 API와 명령행 도구의 예제와 레퍼런스가 준비되어 있다. 자세한 내용은 아래 링크를 통해 확인할 수 있다.